Overview

Figure 1. PinpointQA decomposes the benchmark into four progressively harder tasks for target-centered spatial understanding.
PinpointQA introduces a benchmark centered on small household objects in indoor videos. Rather than only testing whether a model can recognize an object, it evaluates whether the model can determine its presence, ground it with nearby references, describe its location precisely, and finally express that location in a structured form that is directly useful for downstream search.
Human Assistance Evaluation Demo
This lightweight demo mirrors the human assistance setting: users browse several frames, click the target location, and immediately see the elapsed time and response accuracy for each example.
PinpointQA at a Glance
PinpointQA Task Formulation
The benchmark is organized as a progressive capability chain. It starts from target presence verification, moves to reference grounding and fine-grained spatial description, and ends with structured spatial prediction for actionable localization.
Target Presence Verification
Determine whether the target object appears in the video.
Nearest Reference Identification
Identify the reference object closest to the target.
Fine-Grained Spatial Description
Describe the target location with clear spatial language.
Structured Spatial Prediction
Organize the target location into directly usable structured fields.
Data Construction Pipeline
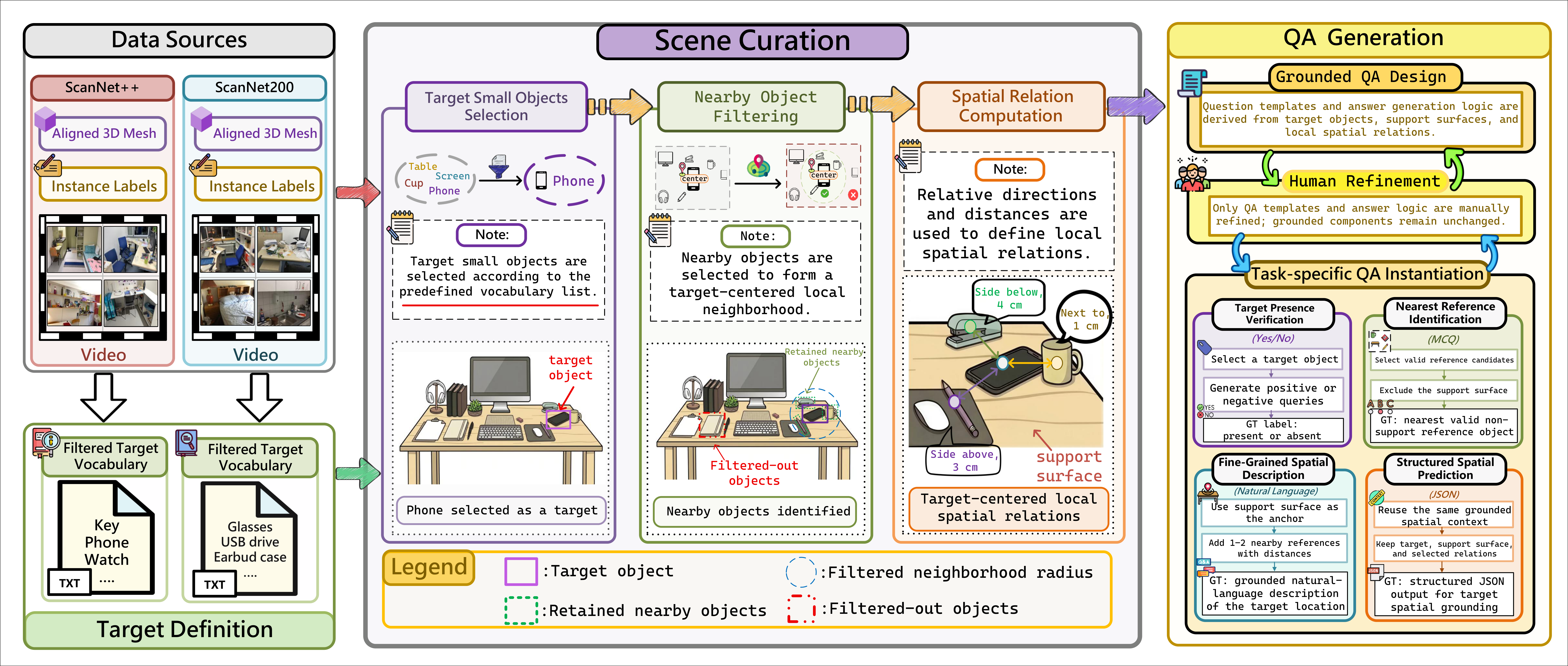
Figure 2. The pipeline connects scene curation, target-centered spatial relation construction, and task-specific QA generation.
PinpointQA is built from ScanNet++ and ScanNet200, combining richly annotated indoor scenes with target-centered spatial reasoning. The pipeline identifies candidate small objects, constructs local spatial relations between the target and nearby references, and then generates aligned QA pairs for TPV, NRI, FSD, and SSP under a unified formulation.
Dataset Statistics
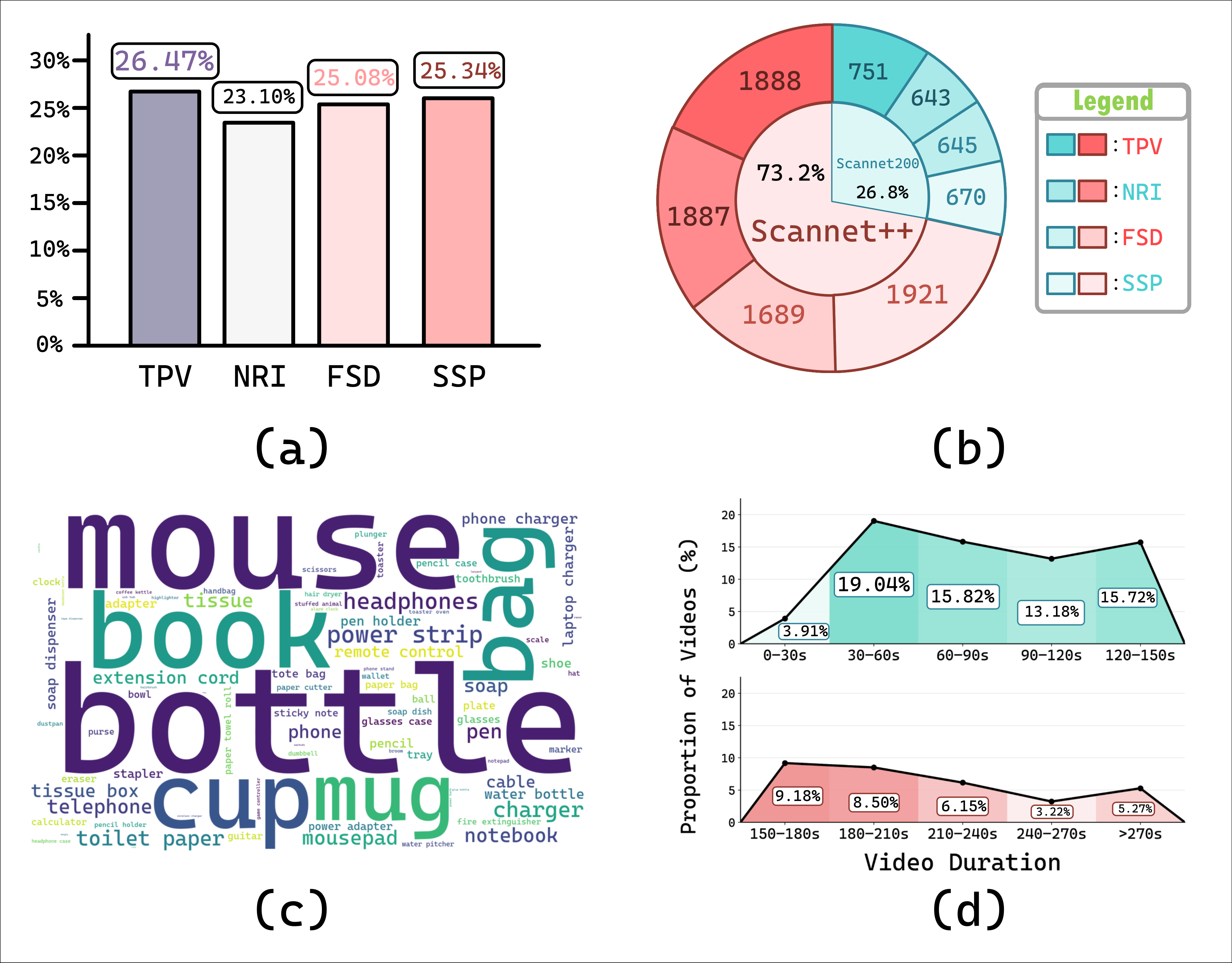
Figure 3. Distribution overview of tasks, data-source composition, target categories, and video duration.
The benchmark maintains a relatively balanced task distribution across TPV, NRI, FSD, and SSP. It covers a wide range of daily small objects, combines samples from both ScanNet++ and ScanNet200, and spans both short-to-medium and longer indoor videos, providing a diverse testbed for small object-centric spatial understanding.
Benchmark Performance
The benchmark reveals a clear performance gap between early-stage target perception and later-stage structured spatial prediction. Fine-tuned open-source models achieve the strongest overall results, while almost all models show a steady decline from TPV to SSP, indicating that executable spatial grounding remains the most challenging part of the task chain.
| Rank | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Qwen3-VL-8B-SFT Fine-tuned | 0.83 | 0.84 | 0.44 | 0.45 | 0.36 | 0.37 | 0.29 | 0.29 | 0.48 | 0.49 | |
| InternVL3.5-8B-SFT Fine-tuned | 0.82 | 0.82 | 0.41 | 0.39 | 0.34 | 0.36 | 0.23 | 0.24 | 0.45 | 0.45 | |
| Kimi K2.5 Proprietary | 0.80 | 0.84 | 0.42 | 0.44 | 0.32 | 0.33 | 0.15 | 0.15 | 0.42 | 0.44 | |
| Qwen3-VL-8B-Instruct Open-source | 0.78 | 0.80 | 0.37 | 0.37 | 0.28 | 0.29 | 0.12 | 0.12 | 0.39 | 0.40 | |
| GPT-5.4 Proprietary | 0.65 | 0.69 | 0.39 | 0.42 | 0.31 | 0.32 | 0.15 | 0.16 | 0.38 | 0.40 | |
| LLaVA-OneVision-1.5-8B Open-source | 0.76 | 0.79 | 0.30 | 0.30 | 0.26 | 0.27 | 0.07 | 0.06 | 0.35 | 0.36 | |
| Cambrian-S-7B Open-source | 0.73 | 0.78 | 0.33 | 0.35 | 0.24 | 0.25 | 0.05 | 0.06 | 0.34 | 0.36 | |
| InternVL3.5-8B-Instruct Open-source | 0.65 | 0.70 | 0.36 | 0.38 | 0.25 | 0.26 | 0.09 | 0.10 | 0.34 | 0.36 | |
| SenseNova-SI-1.3 Open-source | 0.64 | 0.66 | 0.36 | 0.40 | 0.15 | 0.16 | 0.12 | 0.13 | 0.32 | 0.34 | |
| Spatial-MLLM-v1.1 Open-source | 0.52 | 0.51 | 0.30 | 0.30 | 0.21 | 0.20 | 0.00 | 0.00 | 0.26 | 0.25 |
Citation
@article{zhou2026pinpointqa,
title={PinpointQA: A Dataset and Benchmark for Small Object-Centric
Spatial Understanding in Indoor Videos},
author={Zhiyu Zhou and Peilin Liu and Ruoxuan Zhang and
Luyang Zhang and Cheng Zhang and Hongxia Xie
and Wen-Huang Cheng},
year={2026}
}